| www.r-krell.de |
| Webangebot für Schule und Unterricht,
Software, Fotovoltaik und mehr |
Willkommen/Übersicht > Informatik > Java-Seite h)
Informatik mit Java
Teil h): Bau eines Compilers zur Umwandlung von
Java-Quelltext in die 1_AMOR-Merkwort-Sprache
 Die Überschriften a) bis g) verweisen auf die
vorhergehenden Seiten:
Die Überschriften a) bis g) verweisen auf die
vorhergehenden Seiten:
a) Grundlegendes zu Java, benötigte Software (inkl. Downloadadressen) und
Installation
b) Erste Java-Programme (u.a. Autorennen u. Aufzug) sowie Verweise (Links) auf fremde
Java-Seiten
c) Sortieren und Suchen in Java sowie grafische Oberflächen mit der
Java-AWT
d) Adressbuch- und Fuhrpark-Verwaltung sowie Datei-Operationen mit Java
e) Lineare abstrakte Datentypen Keller, Schlange, Liste und Sortierte Liste (sowie
Tiefen- u. Breitensuche)
f) Abstrakter Datentyp Baum ([binärer] Sortierbaum, Rechenbaum, Spielbaum)
g) Abstrakter Datentyp Graph (Adjazenzmatrix u. -listen, typische Fragestellungen, Tiefen- u.
Breitensuche)
Übersicht über diese Seite:
h) Bau eines Compilers zur Umwandlung von Java in die 1_AMOR-Merkwort-Sprache
Eine vollständige Übersicht aller Java-Seiten gibt's auf der
Informatik-Hauptseite!
zum Seitenanfang / zum
Seitenende
Das Compilerprojekt -- Überblick, Intention und Voraussetzungen
Bei diesem Projekt geht es darum, in Java einen Compiler zu schreiben, der Java-Quelltext in Maschinensprache
übersetzt. Dabei wird das praktische Programmieren in Java mit Elementen der Theoretischen Informatik bzw. der
Theorie der formalen Sprachen verknüpft. Außerdem werden Aspekte des maschinennahen Programmierens und der
endlichen Automaten wiederholt.
Da es um das beispielhafte Herausstellen der wichtigsten Prinzipien geht, soll unser Compiler nicht den gesamten
Sprachumfang von Java beherrschen. Vielmehr reicht „Mini-Java", eine Teilmenge von Java mit einigen typischen
Konstrukten. Mini-Java-(Quell-)Programme sollen geprüft und übersetzt werden. Zielsprache der
Übersetzung ist dabei nicht der originale Java-Byte-Code oder echter Intel-Pentium-Assembler, sondern die aus
dem Unterricht bekannte, auf 16 Befehle reduzierte „Maschinensprache" meines 1_AMOR-Modellrechners in der
mnemonischen (=Merkwort-)Darstellung.
Voraussetzung für das Projekt sind neben ausreichenden Java-Fähigkeiten auch Kenntnisse über
(deterministische) endliche Automaten sowie Kenntnis des Modellrechners 1_AMOR und Erfahrungen mit seiner
Programmierung (der Modellrechner ist gratis von meiner Software-Seite herunter zu
laden; das als Datei enthaltene Handbuch vermittelt genug Wissen). Ein Überblick über formale Sprachen und
die Fähigkeit, Syntaxdiagramme zu erstellen oder zumindest zu verstehen, sind hilfreich, können aber auch
anlässlich dieses Projekts erworben werden. Im Informatikunterricht insbesondere des Leistungskurses - der
natürlich weit mehr umfasst, als das hier auf den Seiten „Informatik mit Java" punktuell Herausgestellte -
wurden entsprechende Grundlagen in der Jahrgangsstufe 12 gelegt.
zum Seitenanfang / zum
Seitenende
Mini-Java mit Syntax-Diagramm
Der Compiler soll eine Java-Klasse ohne globale Variablen/Datenfelder (die auch nicht anders wären, als die
erlaubten lokalen Variablen) und mit genau einer Methode übersetzen können. Die Methode soll keine
Parameter erhalten und kein Ergebnis zurückgeben, also immer vom Typ void sein. Innerhalb der Methode
können beliebige Variablen deklariert und benutzt werden, allerdings ausschließlich vom primitiven Typ
int (Ganzzahl). Zuweisungen und die Ausgabeanweisung auf die Konsole (Dos-Box) sind zugelassen; als einzige
Kontrollstruktur ist die (ein- oder zweiseitige) Verzweigung erlaubt. Kommentare (bis zum Rest der Zeile) können
nach // hinzugefügt werden. Das folgende Syntaxdiagramm zeigt den Sprachumfang von „Mini-Java",
einer echten Teilmenge von Java:
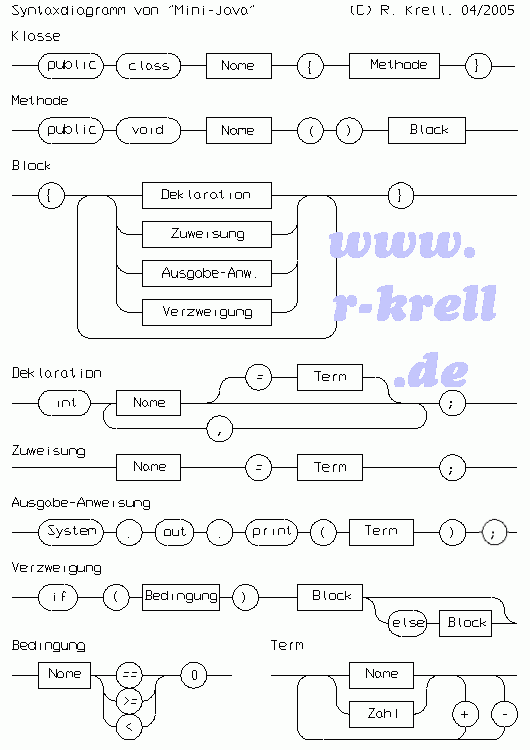 Für Namen gilt, dass sie mit einem Buchstaben anfangen müssen und danach auch Ziffern oder den
Unterstrich enthalten dürfen, während (Ganz-)Zahlen nur aus Ziffern bestehen dürfen. Ein
mögliches Mini-Java-Programm wäre beispielsweise
Für Namen gilt, dass sie mit einem Buchstaben anfangen müssen und danach auch Ziffern oder den
Unterstrich enthalten dürfen, während (Ganz-)Zahlen nur aus Ziffern bestehen dürfen. Ein
mögliches Mini-Java-Programm wäre beispielsweise
public class Beispiel //zum Üben
{
public void losGehts() {
int x; int ypp2s =4;
x= ypp2s - 12 ;
if (x >= 0)
{
System.out.print(x);
// hier wird etwas auf den Bildschirm geschrieben
}
}
} //Programm-Ende |
Natürlich sind unzählige weitere und durchaus sinnvollere Beispiele denkbar.
zum Seitenanfang / zum
Seitenende
Compiler = Scanner + Parser + Variablentabelle +
Codeerzeuger
Der Mini-Java-Quelltext - etwa das gerade im gelben Kasten vorgestellte Beispielprogramm - gelangt z.B. aus dem
Editorfenster oder einer Datei in eine String-Variable, wo es sich als riesige Zeichenkette darstellt, d.h. eine
Aneinanderreihung vieler Schriftzeichen ist.
Die erste Aufgabe des Compilers besteht nun darin, diese Aneinanderreihung von Buchstaben in sinnvolle Einheiten
zu zergliedern, d.h. Zahlen, Schlüsselwörter, Bezeichner und Sonderzeichen (wie etwa Klammern, Semikolon
oder das aus zwei Zeichen bestehende Größer-Gleich-Zeichen) heraus zu filtern und überflüssige
Leerzeichen, Zeilenumbrüche und Kommentare zu ignorieren. Diese Aufgabe übernimmt der
Scanner.
Der Scanner kann zwar eine erste Fehlerkontrolle durchführen, würde aber höchstens merken, wenn Zahlen
fälschlich außer Ziffern auch Buchstaben enthalten oder wenn => an Stelle des richtigen
Größer-Gleich-Zeichens >= geschrieben wurde (lexikalische Kontrolle).
Um zu prüfen, ob die vom Scanner erkannten und gelieferten Sinneinheiten ('Token') in einer vernünftigen
Reihenfolge stehen und den Spezifikationen des Syntaxdiagramms (s.o.) entsprechen, bedarf es der zweiten Komponente
des Compilers, des Parsers. Der Parser nimmt die syntaktische Kontrolle vor und erkennt, ob der
ursprüngliche Quelltext ein erlaubtes Mini-Java-Programm ist oder nicht (oder, für Theorie-Fans: der Parser
löst das Wortproblem für die Mini-Java-Sprache). Sollten Fehler entdeckt werden, sind aussagekräftige
Fehlermeldungen vom Parser wünschenswert.
Wegen des Zwangs, Variablen vor ihrer Verwendung zu deklarieren, bedarf es einer zusätzlichen
Variablentabelle.
Schließlich benötigt der Compiler als letzte Komponente einen Code-Erzeuger, der zum
eingelesenen Mini-Java-Quelltext den passenden Maschinencode bzw. die richtige Übersetzung in die Zielsprache
ausgibt. Hier bzw. im Folgenden stellt der Codeerzeuger keine wirklich eigenständige Komponente dar, sondern
wird später in den Parser integriert (s.u.).
zum Seitenanfang / zum
Seitenende
Scanner
Der Scanner soll bei jedem Aufruf die nächste zusammenhängende Sinneinheit (Token) aus dem Quelltext
erkennen bzw. als Ergebnis liefern. Obwohl in der Java-JDK/SDK die Bibliotheksfunktionen
java.io.StreamTokenizer bzw. java.util.StringTokenizer mitgeliefert werden und evtl. verwendet
werden könnten, wird die Funktion des Scanners von Grund auf erarbeitet. Überlegt man, welche Sinneinheiten
im (Mini-)Java-Quelltext auftreten, so fällt auf:
- Zahlen lassen sich daran erkennen, dass sie mit einer der Ziffern '0' bis '9' anfangen. Danach
dürfen sie auch höchstens mit solchen Ziffern weiter gehen. Ein Vergleichs- oder Rechenzeichen wie
'<', '+' oder '-', eine schließende Klammer ')', ein Semikolon ';' oder ein Leerzeichen bzw. ein
Zeilenumbruch können eine Zahl beenden. Dieses letzte Zeichen ist, sofern es sich nicht um ein Leerzeichen
oder Zeilenumbruch handelt, meist der Beginn eines neuen Tokens. Es muss also beim nächsten Scanner-Aufruf
wieder berücksichtigt werden.
- Wörter - egal ob Schlüsselwörter wie „void" oder „if" oder selbst
vergebene Klassen-, Methoden oder Variablen-Namen, beginnen immer mit einem Buchstaben. Danach können sie mit
Buchstaben oder Ziffern weiter gehen. Andere Zeichen (wie Rechenzeichen, Klammern usw.) signalisieren das Ende des
Wortes und gehören nicht mehr zum Wort, sondern - sofern es sich nicht um Leerzeichen oder den Zeilenvorschub
handelt - zum nächsten Token.
- Was weder mit einer Ziffer noch mit einem Buchstaben beginnt, ist Sonstiges bzw. gilt als
Sonderzeichen. Sonderzeichen sind einstellig (wie Rechenzeichen, Klammern, Semikolon usw.) oder
können ein- oder zweistellig sein: so kann z.B. nach einem '='-Zeichen ein zweites '='-Zeichen für den
Vergleichsoperator kommen (und gehört dann mit zum Token), muss aber nicht (wenn es sich beim Token um das
Zuweisungszeichen handelt). Ähnliches gilt für '>', das der Beginn von Größer-Gleich sein
kann (dann gehört das nachfolgende '='-Zeichen mit zum Token, während evtl. folgende andere Zeichen wie
etwa eine Klammer in „x >(4+3)-2" nicht mehr zum gleichen Token gehören, sondern eine neue, erst beim
nächsten Scanner-Aufruf auszugebende Sinneinheit darstellen.
- Wird ein Schrägstrich '/' erkannt, so kann es sich um ein (in Mini-Java allerdings nicht zugelassenes)
Divisionszeichen, oder - sofern direkt anschließend noch ein zweiter Schrägstrich folgt - um den Beginn
eines Kommentars handeln, der nie als Token ausgegeben wird. Das auszugebende Token beginnt dann erst in der
nächsten Zeile.
Für die Token bietet sich eine eigene Java-Klasse an, damit gleichzeitig die Art des Tokens (durch einen
Kennbuchstaben, nämlich 'z'=Zahl, 'w'=Wort und 's'=Sonstiges bzw. Sonderzeichen) und sein Inhalt als
Zeichenkette übergeben werden können:
// Compiler "Java -> 1_AMOR" -- für IF 13M -- R. Krell, 5.10.04/22.4.2005
-- www.r-krell.de
public class C_Token
{
String inhalt;
char typ; // 'w' = Wort (egal ob Bezeichner oder Schlüsselwort), 'z' =(ganze) Zahl,
// 's' = Sonderzeichen, 'f' = Fehler, 'e' = Programmende
public C_Token (String zeichenfolge, char sorte)
{
inhalt = zeichenfolge;
typ = sorte;
}
} |
Am einfachsten unterscheidet ein endlicher Automat diese Token, wobei jedes aus dem Quelltext gelesene Zeichen
eine Zustandswechsel bewirken kann und am schließlich erreichten Zustand die Art der Sinneinheit erkannt
wird:
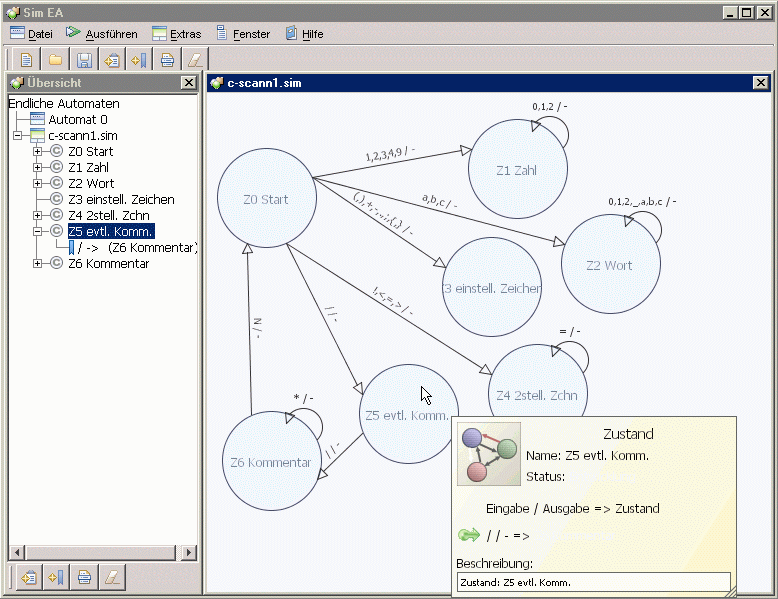
Beim Übergang von Z0 nach Z1, von Z0 nach Z2, von Z1 nach Z1 bzw. von Z2 nach Z2 wurden nicht alle Ziffern
bzw. Buchstaben angegeben, um die Beschriftung der Übergänge übersichtlich zu halten. Der Zustand Z6
wird durch das Zeilenende N = \n verlassen. Zeichen, für die kein Übergang angegeben ist, führen zu
einem Fehler. Der Graph wurde übrigens mit dem Programm „Sim EA" erstellt, das den Automaten auch
ausführen und ein Java-Programm mit der Funktion bzw. zur Simulation des
Endlichen Automaten liefern kann. Das Programm wurde von drei
„Lessing"-Schülern geschrieben und mit dem „JavaStar-Award 2004" ausgezeichnet (der Bericht über die Preisverleihung findet sich im Archiv auf meiner Schulseite
„Lessing-Gymn./BK"; der Download des Programms gelingt (auch im Juli 2011 noch) mit http://www.partner-fuer-schule.nrw.de/javastars/Programme/67_Sim_EA/Sim_EA.zip.
(Ergänzung für Theorie-Fans: Die Funktion eines endlichen Automaten kann immer durch eine reguläre
Grammatik beschrieben werden [Chomsky-Typ 3]).
Die Übersetzung des Automatengraphen in eine simulierende Java-Methode kann schematisch (und von „Sim
EA" normalerweise auch automatisch) erstellt werden: Die Automatentafel wird durch geschachtelte
switch-case-Anweisungen nachgebildet - bzw. hier mit inneren if-Anweisungen, weil in Java die
mehrseitige Verzeigung leider nicht die Angabe von Bereichen wie etwa 'a'..'z','A'..'Z' erlaubt. Hier die komplette
Scanner-Klasse mit der entscheidenden Methode nächstesToken:
- // Compiler "Java -> 1_AMOR" -- für IF 13M -- R. Krell, 5.10.04/22.4.2005
-- www.r-krell.de
public class C_Scanner
{
String quelltext;
int pos;
public C_Scanner (String javatext)
// Konstruktor: erhält Quelltext
und versieht ihn mit Endmarkierung
{
quelltext = javatext + '#';
pos = 0;
}
public C_Token nächstesToken()
// liefert bei jedem Aufruf genau ein
Token
{
int zustand = 0;
String aus = "";
boolean fertig = false;
char type = 'f';
char ein;
do
{
ein = quelltext.charAt(pos);
switch (zustand)
{
case 0 : if (ein >= '0' && ein <= '9') // 0 = Start-Zustand
{
zustand = 1; // Zahl
aus = aus + ein;
type = 'z';
}
else if ((ein >= 'a' && ein <= 'z') || (ein >= 'A' && ein <= 'Z') || (ein == '_'))
{
zustand = 2; // Wort
aus = aus + ein;
type = 'w';
}
else if ((ein=='+')||(ein=='-')||(ein=='(')||(ein==')')||(ein=='{')||(ein=='}')||
(ein=='.')||(ein==';'))
{
zustand = 3; // einstelliges Sonderzeichen
aus = aus + ein;
type = 's';
fertig = true;
}
else if ( (ein=='<')||(ein=='>')||(ein=='=')||(ein=='!') )
{
zustand = 4; // evtl. zweistelliges Sonderzeichen
aus = aus + ein;
type = 's';
}
else if (ein == '/')
{
zustand = 5; // evtl. Kommentar
}
else if ((ein==' ')||(ein=='\n'))
{
zustand = 0; // im Startzustand bleiben: Leerzeichen und/oder Zeilenumbruch überlesen
}
else if (ein=='#')
{
type = 'e'; // Programmtext-Ende
fertig = true;
pos--;
}
else
{
zustand = -1; // Fehler: Unbekanntes Zeichen
aus = aus + ein;
fertig = true;
}
pos ++;
break;
case 1 : if ((ein >= '0' && ein <= '9')) // 1 = Zustand für ganze Zahlen
{
aus = aus + ein;
pos++;
}
else
{
fertig = true;
if ((ein >= 'a' && ein <= 'z') || (ein >= 'A' && ein <= 'Z') || (ein == '_') || (ein > 127))
{
aus = aus + ein;
pos++;
type = 'f'; // Fehler, wenn Buchstaben in Zahl vorkommen
}
}
break;
case 2 : if ((ein >= '0' && ein <= '9') || // 2 = Zustand für Wörter
(ein >= 'a' && ein <= 'z') || (ein >= 'A' && ein <= 'Z') || (ein == '_') || (ein > 127))
{
aus = aus + ein;
pos++;
}
else
{
fertig = true;
}
break;
case 4 : if (ein=='=') // 4 = Zustand für evtl. zweistellige Sonderzeichen
{
aus = aus + ein;
pos++;
}
else
{
fertig = true;
}
break;
case 5 : if (ein=='/') // 5 = Zustand für evtl. Kommentaranfang
{
zustand = 6; // Kommentar
pos++;
}
else
{
fertig = true;
}
break;
case 6 : if (ein=='\n') // 6 = Zustand für Kommentar
{
zustand = 0; // Kommentar-Ende
}
pos++;
break;
default: pos++; fertig = true;
}
} while (!fertig || pos>=quelltext.length());
return (new C_Token (aus, type));
}
public String anfang() //
damit bei einem Fehler der bisherige Quelltext ausgegeben werden kann ..
{ //
.. damit man den Fehler leichter findet
return ("\n"+quelltext.substring(0,pos)+"<<< Fehler s.o.\n");
}
}
Für den Zustand 3 musste kein Fall mehr vorgesehen werden, da bei
einstelligen Sonderzeichen nichts nachkommen kann und daher die Methode nächstesToken direkt beendet
werden kann. Wird der Scanner auf das Beispiel-Programm im gelben Kasten angewendet und immer wieder die Taste
gedrückt, die das nächste Token holt, so ergibt sich schließlich das nachstehende Bild (wobei bei
jeder Sinneinheit im grauen Ausgabefenster zunächst der Kennbuchstabe für die Art bzw. den Typ und nach dem
Doppelpunkt in eckigen Klammern der Inhalt angegeben ist):
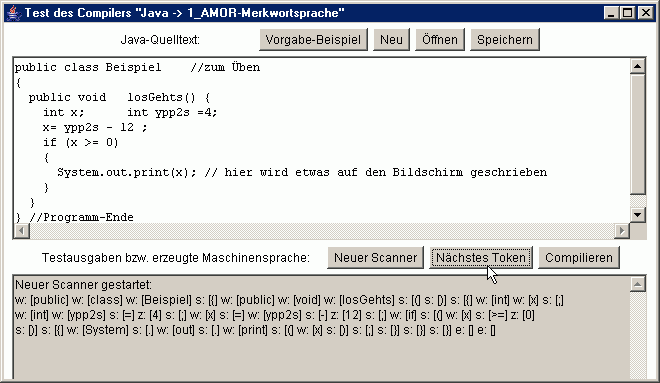
Das zum Schluss zweimal erzeugte Token mit dem Typ 'e' für Ende
hat natürlich keinen Inhalt mehr. Dieses Token käme auch bei allen weiteren Tastendrücken bzw. bei
jedem weiteren Aufruf von nächstesToken.
zum Seitenanfang / zum Seitenende
Parser
Während der vorstehende beschriebene Scanner als endlicher Automat
nicht einmal erkennen kann, ob es zu jeder öffnenden Klammer wieder eine schließende Klammer gibt
(theoretisch sind ja beliebig viele Klammerpaare möglich und damit immer mehr, als der Automat Zustände
hat), muss für die Syntaxkontrolle ein leistungsfähigere Verfahren verwendet werden. Der Parser wird hier
nach dem „Prinzip des rekursiven Abstiegs" gebaut. Die einzige von außen aufzurufende Methode
parseKlasse bearbeitet das erste Konstrukt des oben angegebenen Syntaxdiagramms und ruft intern die dabei
nötige Methode parseMethode auf. Die wiederum ruft zur Kontrolle des in der Methode enthaltenen Blocks
parseBlock auf, wobei sich letztere - evtl. über den Umweg über weitere untergeordnete Methoden
wie etwa parseVerzweigung - auch wieder selbst aufrufen kann, weil Blöcke bekanntlich auch Blöcke
enthalten können.
Da die Verwaltung direkter oder indirekter rekursiver Aufrufe einen
Keller erfordert, wird für den Parser mindestens ein Kellerautomat gebraucht - genau der ist die Maschine, die
zu einer kontextfreien Grammatik gehört (Chomsky-Typ 2): Mini-Java ist kontextfrei, soweit es durch das
Syntaxdiagramm spezifiziert ist. Natürlich kann auch eine noch leistungsfähigere Maschine, wie unser
normaler Computer, zum Parsen benutzt werden. Der im Folgenden angegeben Javatext erscheint nur dadurch etwas
langatmig, dass versucht wurde, bei Fehlern aussagekräftige Meldungen auszugeben. Ansonsten folgt er genau dem
Syntaxdiagramm und ist daher auch ohne große Kommentierung verständlich:
- // Compiler "Java -> 1_AMOR" -- für IF 13M -- R. Krell, 11.10.04,
23.4.2005 -- www.r-krell.de
public class C_Parser // V 0: nur Prüfung, noch ohne Variablentabelle und ohne Codeerzeugung
{
C_Scanner scanner;
public C_Parser (String javatext)
{
scanner = new C_Scanner(javatext);
}
public String parseKlasse ()
{
C_Token token = scanner.nächstesToken();
if (!token.inhalt.equals("public"))
{
return ("Fehler: 'public' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("class"))
{
return ("Fehler: 'class' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (token.typ != 'w')
{
return ("Fehler: Klassenname erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("{"))
{
return ("Fehler: '{' erwartet!"+scanner.anfang());
}
String meldung = parseMethode();
if (meldung.startsWith("Fehler"))
{
return (meldung);
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("}"))
{
return ("Fehler: '}' am Klassenende erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (token.typ != 'e')
{
return ("Fehler: Programmende erwartet"+scanner.anfang());
}
return ("Quelltext erfolgreich compiliert!");
}
private String parseMethode()
{
C_Token token = scanner.nächstesToken();
if (!token.inhalt.equals("public"))
{
return ("Fehler: 'public' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("void"))
{
return ("Fehler: 'void' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (token.typ != 'w')
{
return ("Fehler: Methodenname erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("("))
{
return ("Fehler: '(' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals(")"))
{
return ("Fehler: ')' erwartet!"+scanner.anfang());
}
return (parseBlock());
}
private String parseBlock()
{
C_Token token = scanner.nächstesToken();
if (!token.inhalt.equals("{"))
{
return ("Fehler: '{' erwartet!"+scanner.anfang());
}
String meldung = "";
token = scanner.nächstesToken();
do
{
if (token.inhalt.equals("int"))
{
meldung = parseDeklaration();
token = scanner.nächstesToken();
}
else if (token.inhalt.equals("System"))
{
meldung = parseAusgabe();
token = scanner.nächstesToken();
}
else if (token.inhalt.equals("if"))
{
C_KombiRueckgabe zurück = parseVerzweigung();
token = zurück.gelesenesToken;
meldung = zurück.meldung;
}
else if (token.typ=='w')
{
meldung = parseZuweisung(token);
token = scanner.nächstesToken();
}
else
{
meldung = "Fehler: Beginn einer Deklaration, Zuweisung, Ausgabe oder Verzweigung erwartet!"
+scanner.anfang();
}
}
while (!token.inhalt.equals("}") && !meldung.startsWith("Fehler"));
return (meldung);
}
private String parseDeklaration()
{
// Hinweis: "int" bereits vor Aufruf dieser Methode erkannt!
C_Token token;
do
{
token = scanner.nächstesToken();
if (token.typ != 'w')
{
return ("Fehler: Variablenname erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (token.inhalt.equals("="))
{
C_KombiRueckgabe zurück = parseTerm();
if (zurück.meldung.startsWith("Fehler"))
{
return (zurück.meldung);
}
token = zurück.gelesenesToken;
}
}
while (token.inhalt.equals(","));
if (!token.inhalt.equals(";"))
{
return ("Fehler: ';' nach Deklaration erwartet!"+scanner.anfang());
}
return ("");
}
private String parseZuweisung (C_Token token)
{
if (token.typ!='w')
{
return ("Fehler: Variablenname erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("="))
{
return ("Fehler: '=' erwartet!"+scanner.anfang());
}
C_KombiRueckgabe zurück = parseTerm();
if (zurück.meldung.startsWith("Fehler"))
{
return (zurück.meldung);
}
token = zurück.gelesenesToken;
if (!token.inhalt.equals(";"))
{
return ("Fehler: ';' nach Zuweiung erwartet!"+scanner.anfang());
}
return ("");
}
private String parseAusgabe()
{
// Hinweis: "System" bereits vor Aufruf dieser Methode erkannt!
C_Token token = scanner.nächstesToken();
if (!token.inhalt.equals("."))
{
return ("Fehler: '.' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("out"))
{
return ("Fehler: 'out' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("."))
{
return ("Fehler: '.' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("print"))
{
return ("Fehler: 'print' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("("))
{
return ("Fehler: '(' für Ausgabe erwartet!"+scanner.anfang());
}
C_KombiRueckgabe zurück = parseTerm();
if (zurück.meldung.startsWith("Fehler"))
{
return (zurück.meldung);
}
token = zurück.gelesenesToken;
if (!token.inhalt.equals(")"))
{
return ("Fehler: ')' nach Ausgabe erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals(";"))
{
return ("Fehler: ';' nach Ausgabe-Anweisung erwartet!"+scanner.anfang());
}
return("");
}
private C_KombiRueckgabe parseVerzweigung()
{
// Hinweis: "if" bereits vor Aufruf dieser Methode erkannt!
C_Token token = scanner.nächstesToken();
String meldung = "";
if (!token.inhalt.equals("("))
{
meldung = "Fehler: '(' nach 'if' erwartet!"+scanner.anfang();
}
else
{
meldung = parseBedingung();
if (!meldung.startsWith("Fehler"))
{
token = scanner.nächstesToken();
if (!token.inhalt.equals(")"))
{
meldung = "Fehler: ')' nach Bedingung erwartet!"+scanner.anfang();
}
else
{
meldung = parseBlock();
if (!meldung.startsWith("Fehler"))
{
token = scanner.nächstesToken();
if (token.inhalt.equals("else"))
{
meldung = parseBlock();
if (!meldung.startsWith("Fehler"))
{
token = scanner.nächstesToken();
}
}
}
}
}
}
return (new C_KombiRueckgabe (meldung,token));
}
private String parseBedingung()
{
C_Token token = scanner.nächstesToken();
if (token.typ != 'w')
{
return ("Fehler: Variablenname in der Bedingung erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!(token.inhalt.equals("==")||token.inhalt.equals(">=")||token.inhalt.equals("<")))
{
return ("Fehler: Vergleichsoperator ==, >= oder < erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("0"))
{
return ("Fehler: nur Zahl 0 als Vergleichswert erlaubt!"+scanner.anfang());
}
return("");
}
private C_KombiRueckgabe parseTerm()
{
String meldung = "";
C_Token token;
do
{
token = scanner.nächstesToken();
if (!(token.typ=='w'||token.typ=='z'))
{
meldung = "Fehler: Zahl oder Variable erwartet!"+scanner.anfang();
}
else
{
token = scanner.nächstesToken();
}
}
while ((token.inhalt.equals("+")||token.inhalt.equals("-"))&& !meldung.startsWith("Fehler"));
return (new C_KombiRueckgabe (meldung,token));
}
}
Hinzuweisen ist noch darauf, dass bei manchen Sprachkonstrukten von
Mini-Java nicht sofort klar ist, wann sie enden: Beispielsweise kann die Verzweigung (if-Anweisung) ein-
oder zweiseitig sein. Nach dem ersten Block muss also innerhalb von parseVerzweigung auf jeden Fall ein
weiteres Token von Scanner angefordert werden, um zu prüfen, ob etwa ein else folgt. Enthält
dieses Token aber kein else, so gehört das Token bereits zu einem anderen Sprachkonstrukt, das von
einer anderen Prüfmethode als diesem parseVerzweigung zu bearbeiten ist. parseVerzweigung muss
das zwangsläufig zu viel gelesen Token an die zuständige Stelle weitergeben, was in Java nur über den
Funktionswert geht (oder über eine globale Variable, was aber weniger deutlich wäre). Da der Funktionswert
bei den anderen parse-Methoden aber für die Rückgabe eventueller Fehlermeldungen verwendet wird, ist hier
ein Kombi-Rückgabe nach folgendem Bauplan sinnvoll und oben bei parseVerzweigung ebenso wie etwa auch
bei parseTerm verwendet:
// Compiler "Java -> 1_AMOR" -- für IF 13M -- R. Krell, 31.10.04,
23.4.2005 -- www.r-krell.de
public class C_KombiRueckgabe // für parseXXX-Methoden in C_Parser, weil
// außer einer evtl. Fehlermeldung ggf. noch das bereits gelesene nächste Token
// zurück bzw. weiter gegeben werden muss, das schon zur nächsten Struktur gehört
{
String meldung;
C_Token gelesenesToken;
public C_KombiRueckgabe (String fehler, C_Token token)
{
meldung = fehler;
gelesenesToken = token;
}
} |
zum Seitenanfang / zum Seitenende
Symbol- bzw.
Variablentabelle
Im Syntaxdiagramm von „Mini-Java" nicht aufgeführt, aber
jeder (Java-)Programmiererin und jedem Programmierer bekannt, ist die Tatsache, dass Variablen vor Gebrauch
deklariert werden müssen. Beispielsweise ist das von parseVerzweigung bzw. von parseBedingung
überprüfte Programmstück „if (x>0) {..}" nur richtig, wenn irgendwann vorher die Variable x
mit int x als Ganzzahl definiert wurde und entweder direkt bei der Definition oder aber später, auf
jeden Fall jedoch vor der Bedingung eine gültige Wertzuweisung an x vorgenommen wurde. Durch diese
zusätzliche Forderung ist Mini-Java allerdings nicht mehr kontextfrei, sondern nur noch kontextsensitiv
(Chomsky-Typ 1). Zum Glück muss der vorgestellte Parser deswegen nicht eingestampft werden -- es reicht, ihn
später an wenigen Stellen zu ergänzen.
Dazu wird der Compiler um eine neue Klasse ergänzt, die sich des
Kontextproblems annimmt. Bei der Verwendung eines Bezeichners in der Definition einer gerade Klasse oder Methode oder
bei der Definition einer Variable mit int wird der Bezeichnername in eine Tabelle eingetragen (die für
größere Programme statt wie hier linear sogar zweckmäßigerweise als Baum strukturiert sein
sollte - vgl. meine Seiten „Informatik mit Java", Teile e) und f)). Dabei wird direkt überprüft, ob
evtl. eine unzulässige Neudefinition eines bereits verwendeten Namens oder eine Übereinstimmung mit einem
reservierten Wort (wie etwa if oder void) vorliegt. Gegebenenfalls wird ein entsprechender Fehler
gemeldet.
Wird eine Variable dann z.B. in einer Zuweisung, Ausgabeanweisung oder
in einer Bedingung verwendet, wird in der Variablentabelle nachgeschaut, ob die Variable schon enthalten, also
definiert ist - sonst muss ein Fehlermeldung erzeugt werden. Außer bei der Verwendung links vom
Zuweisungszeichen muss in den gerade genannten Konstrukten die Variable sogar gefüllt sein, um ein fehlerfreies
Programm zu ermöglichen. Dies kann dadurch kontrolliert werden, dass in der Variablentabelle bei jeder in
aufgenommenen Variable durch einen boolean-Wert kenntlich gemacht wird, ob schon eine Zuweisung
stattgefunden hat oder noch nicht. Im Hinblick auf die nachfolgende Codeerzeugung sollte außerdem bei jeder
Variable eine Speicheradresse in die Tabelle festgehalten werden, damit später klar ist, wo die zugewiesenen
Inhalte im Hauptspeicher zu finden sind. Da in Mini-Java alle Variablen vom gleichen Typ int sind, kann hier
auf die zusätzliche Angabe der Größe des belegten Speicherbereichs verzichtet werden.
Die Tabelle darf aber nicht statisch sein, sondern muss der
Lokalität bzw. dem beschränkten Gültigkeitsbereich der Variablen Rechnung tragen: Bekanntlich gelten
Variablen immer nur innerhalb des Blocks / { }-Klammerpaares, in dem sie definiert wurden. Über
holeVarStartNr und setzeVarStartNr können kellerartig in der folgenden Klasse beispielsweise
am Ende eines Blocks leicht alle seit dem Beginn des Blocks definierten Variablen wieder abgeräumt bzw. dem
Zugriff entzogen werden. Für 1_AMOR, dessen 64 Speicherzellen von der Zelle 0 an mit dem Programm gefüllt
werden, wächst die Variablentabelle vom hinteren Ende nach vorne: Die Variablen werden in die Zellen 61, 60, 59,
.. usw. geschrieben (die Zellen 63 und 62 bleiben als Tastatur- und Bildschirmpuffer frei). In der nachstehenden mit
JavaDoc kommentierten Klasse werden außer den Variablen auch (Ganzzahl-)Konstanten verwaltet (in den
1_AMOR-Speicherzellen 48, 47, .. , damit sie bei mehrfachem Auftreten nicht mehrfach gespeichert werden
müssen.
Und da hier ohnehin schon Teile des 1_AMOR-Speicher verwaltet werden,
wurden die Verwaltung schon auf den ganzen Speicher ausgedehnt, d.h. es gibt es im Vorgriff auf den Coderzeuger im
nächsten Kapitel bereits Methoden, mit denen dann (Maschinensprach-)Befehle in die vorderen
1-AMOR-Speicherzellen eingetragen werden können:
- /**
* Die Klasse C_MerkwortCode
* verwaltet den 1_AMOR-Speicher und stellt dem Parser die für die Symboltabellen bzw.
* die für die dort integrierte Coderzeugung benötigten Methoden zur Verfügung --
* für das Projekt Compiler "(Mini-)Java -> 1_AMOR"
*
* @author R. Krell (www.r-krell.de)
* @version für IF13M -- 31.10.04/15.11.04, 23.4.2005
*/
// Compiler "Java -> 1_AMOR" -- für IF 13M -- R. Krell, 31.10.04/11.11.04
public class C_MerkwortCode
{
private String[] zellInhalt = new String[64]; // Speicherzellen-Inhalte des 1_AMOR-Speichers
private String[] varName = new String[71];
// Reihung mit reservierten Wörtern und Variablennamen
private final int konst = 48; // willkürlich gesetzte oberste Adresse für Konstanten
private int zellNr, konstNr; // niedrigste von Variablen bzw. Konsatnen belegte Zelle
private int zeilenNr = -1; // höchste von 1_AMOR-Befehlen belgte Zelle
/**
* Konstruktor : lädt reservierte Wörter und löscht die 1_AMOR-Speicherzellen
* von 0 bis 63 fürs künftige Programm (die Zellen 62 und 63 sind allerdings für
* den Bildschirm- bzw. als Tastaturpuffer reserviert)
*/
public C_MerkwortCode()
{
// es werden nur die Java-Schlüsselwörter als reserviert betrachtet, die auch in Mini-Java vorkommen
varName[70]="public"; varName[69]="class"; varName[68]="void"; varName[67]="int"; varName[66]="System";
varName[65]="out"; varName[64]="print"; varName[63]="if"; varName[62]="else"; // reservierte Wörter
zellNr = 62; // z.Z. niedrigste von einer Variablen besetzte Zelle (weil noch keine Variable
// eingetragen wurde und diese später in den Zellen 61, 60, 59, .. stehen werden)
konstNr = konst+1;
for (int i=konst; i<62; i++)
{
varName[i] = "";
}
for (int i=0; i<64; i++)
{
zellInhalt[i] = "";
}
}
// --------------------- Verwaltung der Variablen und Konstanten ------------------------------
// --------------------- in den Zellen 61, 60, ... bzw. 48, 47, .... --------------------------
/**
* die Variablen belegen die Zellen 61, 60, 59 ... bis hinunter zur VarStartNumer
* (=niedrigste Variablenadresse)
*/
public int holeVarStartNr ()
{
return (zellNr); // ermittelt, ab welcher Zellen-Nummer die Variablen beginnen
}
/**
* hier kann die niedrigste Variablenadresse "mit Gewalt" wieder hoch gesetzt werden,
* damit dadurch die in einem Block definierten Variablen beim Ende des Blocks
* wieder vergessen werden
*/
public void setzeVarStartNr (int nr)
{
zellNr = nr; // setzt Start-Zelle der Variablen ...
}
// ... (und löscht Gültigkeit von Var mit niedrigerer Nummer)
/**
* die Konstanten belegen die Plätze 48, 47, .. bis hinunter zur KonstStartNr
*/
public int holeKonstStartNr ()
{
return (konstNr); // ermittelt, ab welcher Zellen-Nummer die Konstanten beginnen
}
/**
* wird wahr, wenn der übergebene Name (z.B. Klassen- oder Methodenname)
* ein reserviertes Wort ist und damit nicht als Name verwendet werden darf
*/
public boolean istReserviertesWort (String name)
{
for (int i=varName.length-1; i >= 62; i--)
{
if (name.equals(varName[i]))
{
return (true);
}
}
return (false); // kein reserviertes zellInhalt
}
/**
* für die (mit int definierte) Variable wird eine Speicherzelle (Zelle 62 oder
* niedriger) reserviert. Gibt es die Variable schon (oder ist sie ein reserviertes
* Wort), so wird eine Fehlermeldung zurück gegeben.
*/
public String trageVarEin (String name)
{
for (int i=varName.length-1; i >= zellNr; i--)
{
if (name.equals(varName[i]))
{
return ("Fehler: Reserviertes Wort oder bereits definiert");
}
}
zellNr--;
if (zellNr <= konst)
{
return ("Fehler: Kein Speicherplatz mehr für diese und weitere Variablen! ");
}
zellInhalt[zellNr] = zellInhalt[zellNr] + " ;"+name;
varName[zellNr] = name;
return("");
}
/**
* hier wird die Adresse einer früher schon definierten Variable geholt.
* Das Ergebnis ist -1, wenn die Variable noch nicht deklariert sein sollte
*/
public int holeVarAdresse (String name)
{
for (int i=61; i >= zellNr; i--)
{
if (name.equals(varName[i]))
{
return (i);
}
}
return (-1); // nicht gefunden
}
/**
* die übergebene Konstante wird entweder gesucht oder neu eingetragen
* im 1_AMOR-Speicher (Adresse 48 und kleiner) und ihre Adresse zurück gegeben
*/
public int konstantenAdresse (String zahlwort)
{
for (int i=konst; i >= konstNr; i--)
{
if (zahlwort.equals(zellInhalt[i]))
{
return (i);
}
}
konstNr--;
zellInhalt[konstNr] = zahlwort+" ;Konstante "+zahlwort;
return (konstNr);
}
// +++++++++++++++++++++++++++ Eintragen von Befehlen in die Zellen 0, 1, 2, ... ++++++++++++++++++++++++++++
/**
* die aktuelle Zellennummer (wo gerade der letzte 1_AMOR-Befehl eingetragen wurde)
*/
public int befehlsNummer()
{
return (zeilenNr);
}
/**
* trägt den übergebenen 1_AMOR-Befehl in die nächste freie Speicher-Zelle ein
* (Start ab Zelle 0) und erhöht automatisch die befehlsNummer
*/
public void trageBefehlEin (String maschinenBefehl)
{
zeilenNr++;
zellInhalt[zeilenNr] = maschinenBefehl;
}
/**
* schreibt hinten an den in Zelle nr gespeicherten Befehl den übergebenen
* Zusatz dran. Wichtig, damit z.B. bei einem Sprung-Befehl nach der Coderzeugung
* für den nachfolgenen Block noch die Adresse der auf den Block folgenden
* Zeile/Zelle nachgetragen werden kann.
*/
public void ergänzeBefehl (int nr, String befehlszusatz)
{
zellInhalt[nr] = zellInhalt[nr] + " " + befehlszusatz;
}
/**
* zeigt den in der Zelle nr eingetragenen Befehl
*/
public String holeBefehl(int nr)
{
return(zellInhalt[nr]);
}
/**
* gibt das gesamte Maschinenprogramm inkl. Konstanten und Variablenspeicher
* zurück -- und zwar ohne Leerzeilen, dh. für die Bildschirmausgabe optimiert
*/
public String zeigeCode()
{
String aus = "";
for (int i=0; i<= zeilenNr; i++)
{
if (!zellInhalt[i].equals(""))
{
aus = aus + i+".) " + zellInhalt[i] + "\n";
}
}
for (int i=konstNr; i<62; i++)
{
if (!zellInhalt[i].equals(""))
{
aus = aus + i+".) " + zellInhalt[i] + "\n";
}
}
aus = aus + "62.) ;Bildschirm\n63.) ;Tastatur\n";
return (aus);
}
/**
* gibt das gesamte Maschinenprogramm (Zellen 0..63) mit Leerzeilen und
* "harten" Zeilenvorschüben zurück -- zum Speichern als 1-AMOR-Datei
* (mit der Endung 1_M)
*/
public String nenneKomplettCode() //für 1_AMOR
{
String aus = "";
for (int i=0; i<62; i++)
{
aus = aus + zellInhalt[i] + (char)13+"\n"; //zusätzliche Zeilenschaltung für Dos-Text
}
aus = aus + " ;Bildschirm"+(char)13+"\n ;Tastatur\n"+(char)13
+"\nEnde des \"1_AMOR\"-Maschinenprogramms."+(char)13+"\n";
return (aus);
}
}
In der vorstehenden Klasse C_Merkwortcode gibt es allerdings
noch nicht die zuvor angesprochenen Flags samt zugehöriger Methoden, um Zuweisungen für Variable zu
registrieren. Deshalb kann man vor Gebrauch einer Variablen auf der rechten Seite einer Zuweisung, in einer Bedingung
oder in einer Ausgabeanweisung auch nicht nachfragen, ob die Variable schon einen Wert enthält, d.h.
initialisiert wurde. Legt man Wert auf diese Fähigkeit, muss die Klasse noch entsprechend ergänzt
werden.
zum Seitenanfang / zum Seitenende
Codeerzeuger
Statt den zu compilierenden (Mini-Java-)Quelltext nach erfolgreicher
Syntaxüberprüfung durch den Parser noch ein zweites Mal durchzugehen, um dann die Übersetzung in die
Zielsprache anzufertigen, kann dieser Vorgang bequem in den Parser integriert werden. Im Unterricht ist es
wahrscheinlich sinnvoll, vor der Übersetzung in eine Maschinensprache eine Übersetzung in weniger
formalisierten deutschen Klartext anzufertigen. Gleichzeitig soll der Parser zur Kontrolle, ob benutzte Variable
zuvor deklariert wurden, die im Objekt tab (vom Typ der Klasse C_Merkwortcode) verwaltete
Variablentabelle benutzen Die notwendigen Ergänzungen in der oben bereits vorgestellten Parser-Version werden in
grüner Farbe am Beispiel von parseZuweisung bzw. parseTerm gezeigt:
private String parseZuweisung (C_Token token)
{
if (token.typ!='w')
{
return ("Fehler: Variablenname erwartet!"+scanner.anfang());
}
int adr = tab.holeVarAdresse(token.inhalt); // hier wird überprüft, ob die Variable..
if (adr < 0) //.. im letzten Token bereits deklariert wurde (adr >= 0) der nicht
{
return ("Fehler: Variable nicht definiert (oder unzuläss. Name)!"+scanner.anfang());
}
String varName = token.inhalt;
token = scanner.nächstesToken();
if (!token.inhalt.equals("="))
{
return ("Fehler: '=' erwartet!"+scanner.anfang());
}
C_KombiRueckgabe zurück = parseTerm(); // Aufruf von parseTerm
if (zurück.meldung.startsWith("Fehler"))
{
return (zurück.meldung);
}
token = zurück.gelesenesToken;
if (!token.inhalt.equals(";"))
{
return ("Fehler: ';' nach Zuweiung erwartet!"+scanner.anfang());
}
ausgabe = ausgabe + " wird zugewiesen an "+varName+"\n"; // Erzeugen von deutschem Text ..
// .. an Stelle von Maschinensprache. Die rechte Seite der Zuweisung wurde bereits
vom ..
// .. oben aufgerufenen parseTerm (s.u.) in den
globalen String ausgabe geschrieben
return ("");
} |
private C_KombiRueckgabe parseTerm()
{
String meldung = "";
C_Token token;
String term = "Term "; // für die Zielsprache (hier
deutscher Text statt Maschinencode)
do
{
token = scanner.nächstesToken();
if (!(token.typ=='w'||token.typ=='z'))
{
meldung = "Fehler: Zahl oder Variable erwartet!"+scanner.anfang();
}
else
{
int adr;
if (token.typ=='w')
{
adr = tab.holeVarAdresse(token.inhalt);
if (adr < 0) // falls Variable bisher nicht definiert
{
meldung = "Fehler: Variable nicht definiert (oder unzuläss. Name)!"
+scanner.anfang();
}
}
else // im Token steht eine feste Zahl. Auch Konstanten werden..
{ // ..nur einmal gespeichert und bei Bedarf mehrfach verwendet
adr = tab.konstantenAdresse(token.inhalt);
}
term = term + token.inhalt; // Variable oder (Zahl-)Konstante
token = scanner.nächstesToken();
term = term + token.inhalt; // evtl. Rechenzeichen
(oder Ende)
}
}
while ((token.inhalt.equals("+")||token.inhalt.equals("-"))&& !meldung.startsWith("Fehler"));
ausgabe = ausgabe + term; // Zuweisung an globale Variable für erzeugten dt.
Text
return (new C_KombiRueckgabe (meldung,token));
} |
Nach solchen Vorübungen und einer kurzen Wiederholung der
Maschinensprache bzw. einen evtl. Blick in das Handbuch zum Modellrechner 1_AMOR, wo im Kapitel B die typischen
Programmkonstrukte und Kontrollstrukturen an Beispielen zusammen gestellt sind
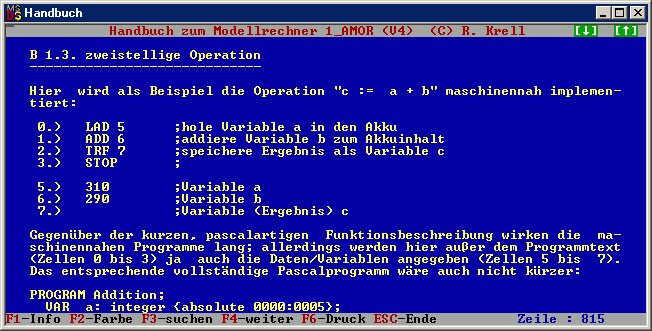
(in Java würde die Zuweisung anders als in Pascal nur „c = a+b;" heißen), kann dann insbesondere
unter Verwendung der Methode trageBefehlEin (aus der dem jetzt besser code genannten Objekt vom Typ
der Klasse C_Merkwortcode mit der Variablentabelle und den Methoden zum Eintragen der Befehle) der
1_AMOR-Zieltext erzeugt werden. Es wird der Anfang der entsprechend ergänzten bzw. veränderten
Parser-Klasse mit parseKlasse und den beiden in den Vorübungen schon dargestellten parse-Methoden
gezeigt. Da für unterschiedliche Rechenoperationen verschiedene Maschinenbefehle nötig sind, musste
gegenüber der Übersetzung in deutschen Text eine mehrseitige Verzeigung in parseTerm eingebaut
werden. Außerdem wurde der Mangel behoben, dass im deutschen Text ein evtl. beendendes Semikolon oder anderes
Zeichen sofort als evtl. Rechenzeichen zum Term-Text hinzugefügt wird.
- // Compiler "Java -> 1_AMOR" -- für IF 13M -- R. Krell, 31.10.04/11.11.04/23.4.2005 -- www.r-krell.de
public class C_Parser // V 3: Prüfung mit Variablentabelle und 1_AMOR-Merkworttext
{
C_Scanner scanner;
C_MerkwortCode code = null;
public C_Parser (String javatext)
{
scanner = new C_Scanner(javatext);
code = new C_MerkwortCode();
}
public String liefereMaschinensprache()
{
if (code==null || !code.holeBefehl(code.befehlsNummer()).equals("STOP"))
{
return ("Noch nicht erfolgreich compiliert!");
}
else
{
return (code.nenneKomplettCode());
}
}
public String parseKlasse ()
{
code = new C_MerkwortCode();
C_Token token = scanner.nächstesToken();
if (!token.inhalt.equals("public"))
{
return ("Fehler: 'public' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("class"))
{
return ("Fehler: 'class' erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (token.typ != 'w')
{
return ("Fehler: Klassenname erwartet!"+scanner.anfang());
}
if (code.istReserviertesWort(token.inhalt))
{
return ("Fehler: Klassenname darf kein Java-Schlüsselwort sein!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("{"))
{
return ("Fehler: '{' erwartet!"+scanner.anfang());
}
String meldung = parseMethode();
if (meldung.startsWith("Fehler"))
{
return (meldung + code.zeigeCode()); //!
}
token = scanner.nächstesToken();
if (!token.inhalt.equals("}"))
{
return ("Fehler: '}' am Klassenende erwartet!"+scanner.anfang());
}
token = scanner.nächstesToken();
if (token.typ != 'e')
{
return ("Fehler: Programmende erwartet"+scanner.anfang());
}
code.trageBefehlEin("STOP");
return ("Quelltext erfolgreich compiliert!\n" + code.zeigeCode());
}
...
private String parseZuweisung (C_Token token)
{
if (token.typ!='w')
{
return ("Fehler: Variablenname erwartet!"+scanner.anfang());
}
int adr = code.holeVarAdresse(token.inhalt);
if (adr < 0)
{
return ("Fehler: Variable nicht definiert (oder unzuläss. Name)!"+scanner.anfang());
}
String varName = token.inhalt;
token = scanner.nächstesToken();
if (!token.inhalt.equals("="))
{
return ("Fehler: '=' erwartet!"+scanner.anfang());
}
C_KombiRueckgabe zurück = parseTerm();
if (zurück.meldung.startsWith("Fehler"))
{
return (zurück.meldung);
}
token = zurück.gelesenesToken;
if (!token.inhalt.equals(";"))
{
return ("Fehler: ';' nach Zuweiung erwartet!"+scanner.anfang());
}
code.trageBefehlEin("TRF "+code.holeVarAdresse(varName));
return ("");
}
private C_KombiRueckgabe parseTerm()
{
String meldung = "";
C_Token token;
char verknüpfung = '1'; // noch keine Vernüpfung; erste Variable bzw. erste Zahl
String befehl = "??"; // wird später richtig gefüllt
do
{
token = scanner.nächstesToken();
if (!(token.typ=='w'||token.typ=='z'))
{
meldung = "Fehler: Zahl oder Variable erwartet!"+scanner.anfang();
}
else
{
int adr;
if (token.typ=='w')
{
adr = code.holeVarAdresse(token.inhalt);
if (adr < 0)
{
meldung = "Fehler: Variable nicht definiert (oder unzuläss. Name)!"
+scanner.anfang();
}
}
else
{
adr = code.konstantenAdresse(token.inhalt);
}
switch (verknüpfung)
{
case '1' : befehl = "LAD"; break;
case '+' : befehl = "ADD"; break;
case '-' : befehl = "SUB"; break;
}
code.trageBefehlEin(befehl+" "+adr);
token = scanner.nächstesToken();
verknüpfung = token.inhalt.charAt(0);
// zwar gemerkt, aber noch ohne
MaschinenCode
}
}
while ((token.inhalt.equals("+")||token.inhalt.equals("-"))&& !meldung.startsWith("Fehler"));
return (new C_KombiRueckgabe (meldung,token));
}
...
Dass dieser Compiler in seiner letzten Ausbaustufe tatsächlich
funktioniert, lässt sich mit Hilfe der bereits beim Scanner gezeigten Testoberfläche ausprobieren, wenn
dort die Schaltfläche „Compilieren" betätigt wird:
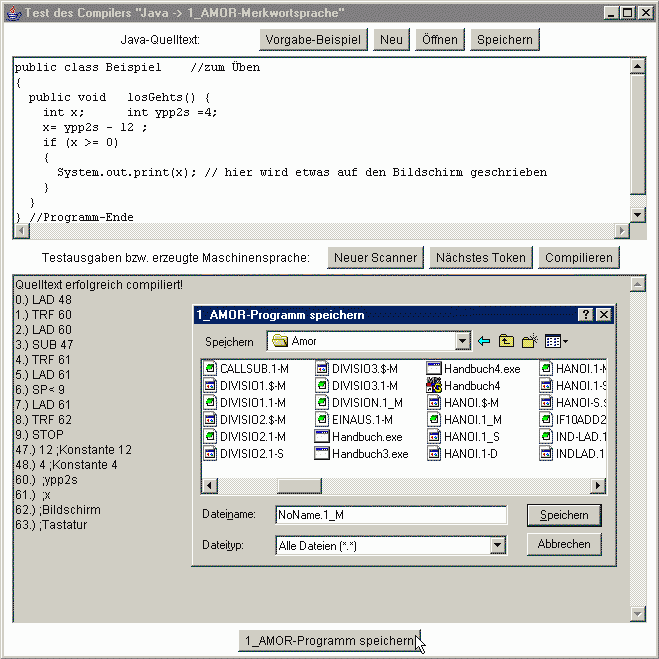 Wird der für das „Mini-Java"-Beispielprogramm erzeugte
1_AMOR-Text sogar (wie gezeigt) in einer Datei gespeichert, so lässt er sich anschließend in den
Modellrechner laden und dort problemlos und auf Wunsch schrittweise unter Anzeige aller Datenflüsse
ausführen. Weil die im Quelltext angegebene Bedingung „if (x >= 0) .." nicht erfüllt ist (x hat
den Wert -8 und ist daher nicht >= 0), wird nichts auf dem Bildschirm ausgegeben - die Zelle 62 bleibt leer bzw.
mit Nullen gefüllt:
Wird der für das „Mini-Java"-Beispielprogramm erzeugte
1_AMOR-Text sogar (wie gezeigt) in einer Datei gespeichert, so lässt er sich anschließend in den
Modellrechner laden und dort problemlos und auf Wunsch schrittweise unter Anzeige aller Datenflüsse
ausführen. Weil die im Quelltext angegebene Bedingung „if (x >= 0) .." nicht erfüllt ist (x hat
den Wert -8 und ist daher nicht >= 0), wird nichts auf dem Bildschirm ausgegeben - die Zelle 62 bleibt leer bzw.
mit Nullen gefüllt:
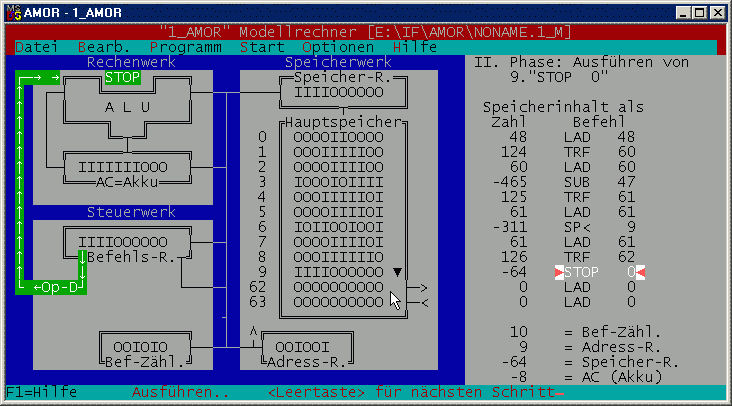
Eine schöne Bestätigung für den erfolgreichen Compilerbau!
zum Seitenanfang / zum Seitenende
Verweise
Bevor Sie einen der folgenden Verweise anklicken, sollten Sie erst
meine Seite zu Ihren Favoriten hinzufügen (Microsoft Internet Explorer) oder ein Lesezeichen setzen (Netscape),
damit Sie anschließend sicher hierher zurück finden! Natürlich kann ich für den Inhalt fremder
Seiten keine Verantwortung übernehmen. Wenn ein Verweis nicht funktioniert, dort inzwischen andere Inhalte zu
sehen sind oder wenn Sie mir weitere gute Seiten empfehlen können, bitte ich um eine kurze Nachricht!
Hinweis: fremde Seiten werden in einem neuen
Browser-Fenster geöffnet, eigene in diesem. Geschieht beim Anklicken eines Verweises scheinbar nichts, wird das
neue Fenster vermutlich vom aktuellen Fenster verdeckt -- bitte per Task-Leiste ins neue Fenster
wechseln!
| Meine „Software"-Seite |
für den (kostenlosen)
1_AMOR-Modellrechner |
| JavaStars-Downloadseite |
für das oben vorgestellte Programm
„Sim_EA" (und weitere preisgekrönte Programme - Stand Juli 2007. Achtung: da die interne Struktur des
'Partner-für-Schule'-Webangebots häufiger verändert wird, muss ggf. gesucht werden - vermutlich
einfach nur bis SimeEA runter gescrollt werden. Bitte schicken Sie mir eine Nachricht,
wenn das Programm gar nicht mehr zu finden ist! |
| Formale Sprachen und
Automaten |
Empfehlenswerte Seiten des
Hohenstaufen-Gymnasiums, Kaiserslautern. Enthalten sind viele Informationen zu formalen Sprachen und Automaten,
aber auch zur gesamten Informatik. |
Ihnen gefällt diese Seite bzw. mein Web-Angebot? Sie wollen auch
andere auf diese Seite aufmerksam machen? Mit Klick auf den Verweis „per e-Mail weiter empfehlen" ganz unten
auf dieser Seite können Sie eine e-Mail mit der URL versenden!
zurück zur
Informatik-Hauptseite
(Die anderen „Informatik mit Java"-Seiten
werden entweder mit dem Menü hier am Seitenanfang oder
am besten auch auf der Informatik-Hauptseite ausgewählt)